PinnedWhy Less Human = More AI ProgressReinforcement Learning with verifiable rewards (RLVR) vs. Supervised Fine-Tuning (SFT)Feb 20Feb 20
PinnedOpenAI’s o1 Model: Paying for AI’s Internal MonologueFuture of AI, where the thoughts are invisible, and meter is alway ON !Sep 13, 2024Sep 13, 2024
PinnedCalculate : How much GPU Memory you need to serve any LLM ?Just tell me how much GPU Memory do i need to serve my LLM ? Anyone else looking for this answer ? Read On …Jul 11, 20246Jul 11, 20246
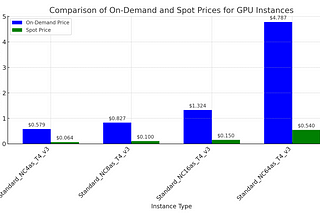
PinnedDead Cheap LLM Inferencing in ProductionA guide for leveraging Spot GPU Instances for Cost-Effective LLM Inference WorkloadsJul 7, 2024Jul 7, 2024
PinnedPublished inTowards DevRedis-GoLang-React Sample Chat App on OpenShift (Kubernetes)Here is my journal to deploy a sample Redis-GoLang-React Real Time chat application on OpenShiftJan 9, 2022Jan 9, 2022
SheetStack : OpenSource Tool to expose Google Sheets via APIs 🚀At Scogo, we have always been avid consumers of open-source technologies, building solutions that leverage the power of the community. Now…Dec 27, 20241Dec 27, 20241
AI and the Future of Programming: A Developer’s PerspectiveI just got out of the Xtremepython Conference (virtually), where I was part of a panel discussing “The AI Revolution in Coding: Tools…Nov 19, 2024Nov 19, 2024
Prompt Caching: Because Who Has Time for Slow AI?Prompt Caching : First introduced by Anthropic , adopted by OpenAI … and LLama to follow soonOct 2, 2024Oct 2, 2024
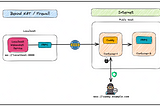
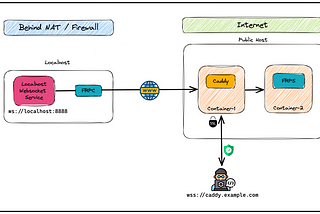
Exposing Local Web-socket connection Securely with FRP & CaddyA step-by-step implementation guideApr 20, 2023Apr 20, 2023