PinnedKaran SinghCalculate : How much GPU Memory you need to serve any LLM ?Just tell me how much GPU Memory do i need to serve my LLM ? Anyone else looking for this answer ? Read On …Jul 11Jul 11
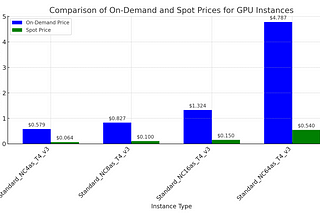
PinnedKaran SinghDead Cheap LLM Inferencing in ProductionA guide for leveraging Spot GPU Instances for Cost-Effective LLM Inference WorkloadsJul 7Jul 7
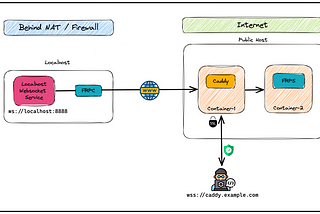
PinnedKaran SinghExposing Local Web-socket connection Securely with FRP & CaddyA step-by-step implementation guideApr 20, 2023Apr 20, 2023
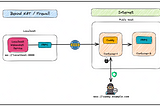
PinnedKaran SinghinTowards DevRedis-GoLang-React Sample Chat App on OpenShift (Kubernetes)Here is my journal to deploy a sample Redis-GoLang-React Real Time chat application on OpenShiftJan 9, 2022Jan 9, 2022
PinnedKaran SinghLet’s do GitOps using ArgoCD on OpenShiftArgo CD is a declarative, GitOps continuous delivery tool for Kubernetes (OpenShift). Argo CD follows the GitOps pattern of using Git…Jul 4, 2021Jul 4, 2021